

No video for this one - just a quick review of Big-O.
When I started writing The Imposter’s Handbook, this was the question that was in my head from the start: what the f is Big O and why should I care?I remember giving myself a few weeks to jump in and figure it out but, fortunately, I found that it was pretty straightforward after putting a few smaller concepts together.
Big O is conceptual. Many people want to qualify the efficiency of an algorithm based on the number of inputs. A common thought is if I have a list with 1 item it can’t be O(n) because there’s only 1 item so it’s O(1). This is an understandable approach, but Big O is a technical adjective, it’s not a benchmarking system. It’s simply using math to describe the efficiency of what you’ve created.
Big O is worst-case, always. That means that even if you think you’re looking for is the very first thing in the set, Big O doesn’t care, a loop-based find is still considered O(n). That’s because Big O is just a descriptive way of thinking about the code you’ve written, not the inputs expected.
An Amazingly Useful Concept
I’m glad I took the time to learn Big O because I find myself thinking about it often. If you’ve always wondered about Big O but found the descriptions a bit too academic, I’ve put together a bit of a Common Person’s Big O Cheat Sheet, along with how you might use Big O in your every day work.
Rather than base this on arrays and simplified nonsense, I’ll share with you a situation that I was in just a year ago: choosing the right data structure in Redis. If you’ve never used Redis before, it’s a very basic key-value store that works in-memory and can optionally persist your data to disk.
When you work in a relational database like PostgreSQL, MySQL, or SQL Server you get a single data structure: the table. Yes, there are data types, sure, but your data is stored in a row separated by columns, which is a data structure.
Redis gives you a bit more flexibility. You get to choose the data structure that fits your programming need the best. There are a bunch of them, but the ones I find myself using most often are:
- String. With this structure you store a string value (which could be JSON) with a single key.
- Set. A Set in Redis is a bunch of unordered, unique string values.
- Sorted Set. Just like a Set, but sorted.
- List. Non-unique string values sorted by order of insertion. These things operate like both stacks and queues.
- Hash. A set of string values identified by “sub keys”. You can think of this as a JSON object with values being only strings.
Why are we talking about Redis when this post is about Big O? Because Redis and Big O go hand in hand. To choose the right data structure for your needs, you need to dig you some Big O (whether you know it’s Big O or not).
FINDING SOMETHING IN A SHOPPING CART
Let’s say you’re tasked with storing Shopping Cart data in Redis. Your team has decided that an in-memory system would work well because it’s fast and it doesn’t matter if cart data is lost if the server blows up.
The question is: how do you store this information? Here’s what’s required:
- Finding the cart quickly by key
- CRUD operations on each item within the cart
- Finding an item in the cart quickly
- Iterating over each item in the cart
Believe it or not, you’re thinking in Big O right now and you might not even know it. I used the words “quickly” and “iterate” above, which may or may not mean something to you in a technical sense. The thing I was trying to convey by using the word “quickly” is that I want to get to the cart (or an item within it) directly, without having to jump through a lot of hoops.
Even that description is really arm-wavy, isn’t it? We can dispose of the arm-waving by thinking about things in terms of operations per input. How many operations does my code need to perform to get to a single cart from the set of all carts in Redis?
ONLY ONE OPERATION: O(1)
The cool thing about Redis is that it’s a key-value store. To find something, you just need to know its key. You don’t have to run a loop or do some complex find routine – it’s just right there for you.
When something requires only one operation we can say that directly: my code for finding a shopping cart is on the order of 1 operation. If we want to be Big O about it, we can say it’s order 1, or “O(1)”. It doesn’t matter how many carts are in our Redis database either! We have a key and we can go right to it.
A more precise way to think about this is to use the term “constant time”. It doesn’t matter how many rows of data are in our database (or, correspondingly, how many inputs to our algorithm) – the algorithm will run in constant time which doesn’t change.
What about the items in the cart itself?
LOOPING OVER A SET: O(N)
We know that our cart will need to store 0 to n items. I’m using n here because I don’t know how many items that will be – it varies per customer.
I can use any of Redis’s data structures for this:
- I can store a JSON blob in a String, identified by a unique cart key
- I can store items in a Set or Sorted Set, with each item being a bit of JSON that represents a
CartItem - I can store things in a List in the same way as a set
- I can store things in a Hash, with each item having a unique sub key
When it comes to items in the cart, we need to be able to do CRUD stuff but we also need to be able to find an item in the cart “as quickly as possible”. If we use a String (serializing it into JSON first), a Set or a List we’ll need to loop over every item in a cart in order to find the one we’re looking for.
Rather than saying “need to loop over every item”, we can think about things in terms of operations again: if I use a Set or a List or a String I’ll need to have one operation for every n items in my cart. We can also say that this is “order n“, or just O(n).
You can spot O(n) operations easily by simply looking for loops in your code. This is my rule of thumb: “if there’s a loop, it’s O(n)”.
LOOPING WITHIN A LOOP: O(N^2)
Let’s say we decided to keep things simple and deal with problems as they arise so we chose a Set, allowing us to dump unique blobs of JSON data that we can loop over if we need to. Unfortunately for us, this caused some issues:

By changing the quantity in our CartItem we have made our JSON string unique, causing duplication. We need to remove these duplications now, otherwise our customers won’t be happy.
Simple enough to do: we just loop over the items within a cart, and then loop over the items one more time (skipping the current loop index) to see if there’s a match on sku. This is a classic brute force algorithm for deduping an array. That’s a lot of words to describe this nested loop algorithm and we can do better if we use Big O.
Thinking in terms of operations, we have n operations per n items in our cart. That’s n * n operations, which we can shorthand to “order n squared” or O(n^2). Put another way: deduping an array is an O(n^2) operation, which isn’t terribly efficient.
As I said before, I like to think of these things in terms of loops. My rule of thumb here is that if I have to use a loop within a loop, that’s O(n^2). Another rule of thumb is that the term “brute force” almost always denotes an O(n^2) algorithm that uses some kind of nested loop.
INDEXING A DATABASE TABLE AND O(LOG N).
If you’ve ever worked on a larger project with a DBA, you’ve probably been barked at for querying a table without utilizing an index (a “fuzzy” search, for instance). Have you ever wondered what the deal is? I have. I was that DBA doing the barking!
Here’s the thing: tables tend to grow over time. Let’s say that our commerce site is selling independent digital films and our catalog is constantly growing. We might have a table called film filled with ridiculous test data that we want to query based on title. Unfortunately, we don’t have an index just yet and our query is beginning to slow down. We decide to ask PostgreSQL what’s going on using EXPLAIN and ANALYZE:
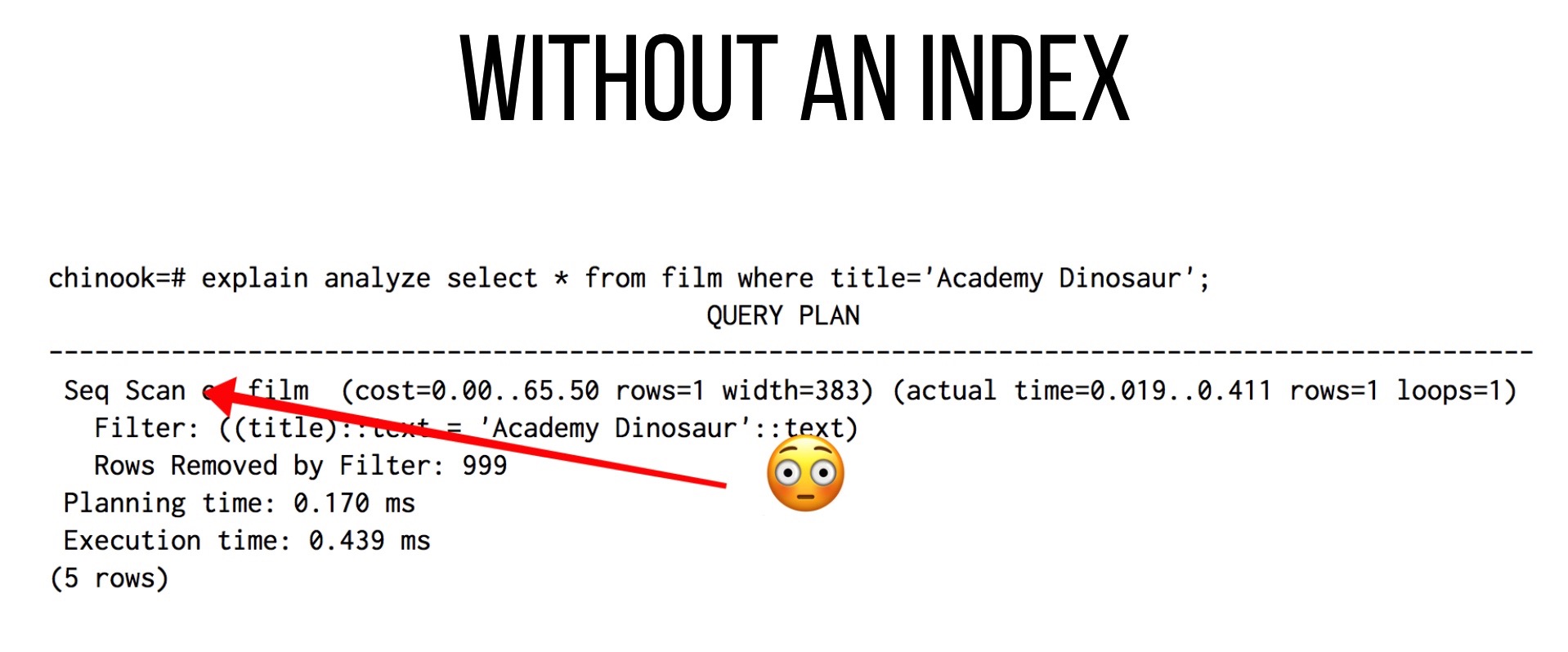
Our database is doing what’s called a “Sequential Scan”. In SQL Server land this is called a “Full Table Scan” and it basically means that Postgres has to loop over every row, comparing the title to our query argument.
In other words: a Sequential Scan is a loop over every item which means it’s O(n), where n represents the number of rows in our table. As our table grows, the efficiency of this algorithm goes down linearly.
It’s easy to improve the performance here by adding an index:
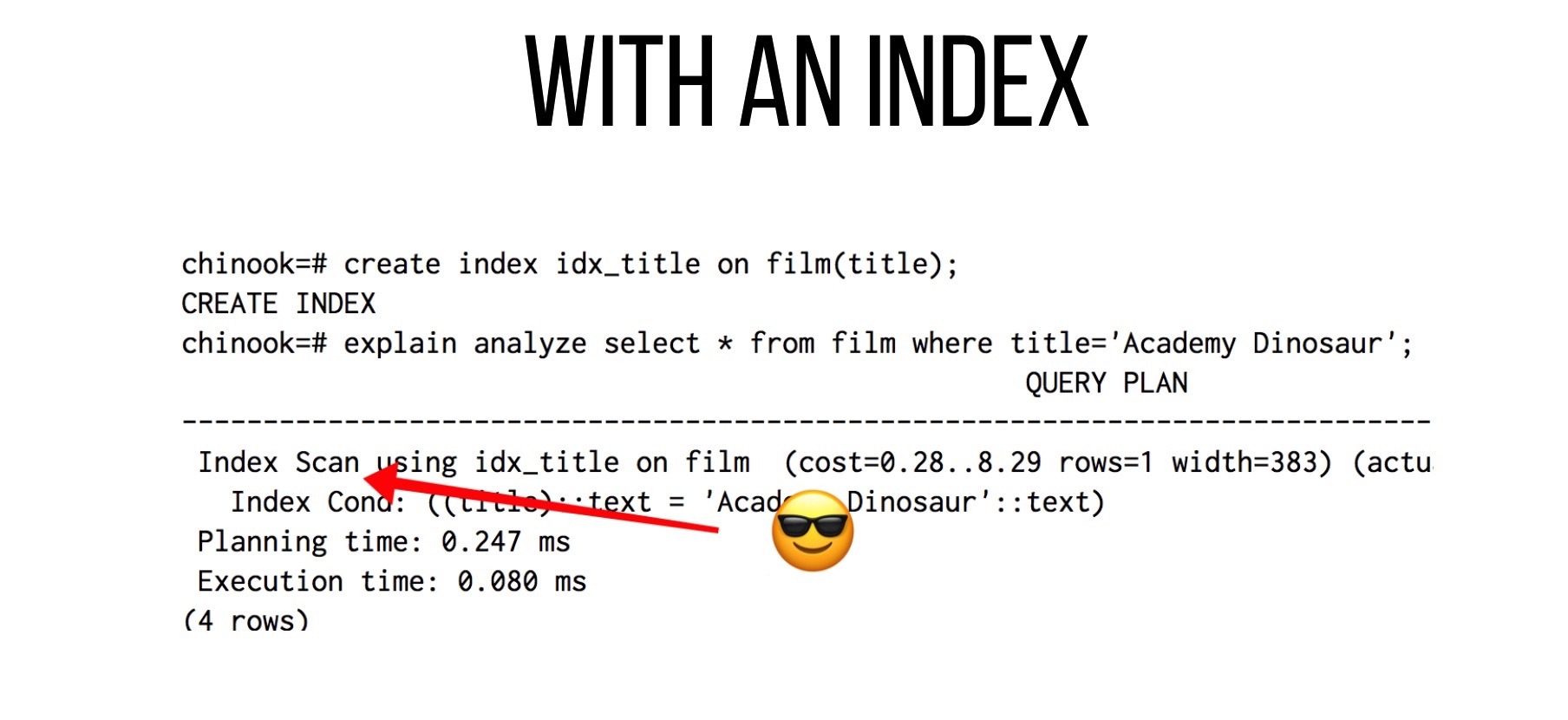
Now we’re using an Index Scan, which is, I suppose, much faster. But how much? And how does it work?
Under the covers, most databases use a version of an algorithm called binary search – I made a video about this and other algorithms which you can watch right here if you want. For binary search to work properly, you have to sort the list of things you’re working with. That’s exactly what Postgres does when you first create the index:
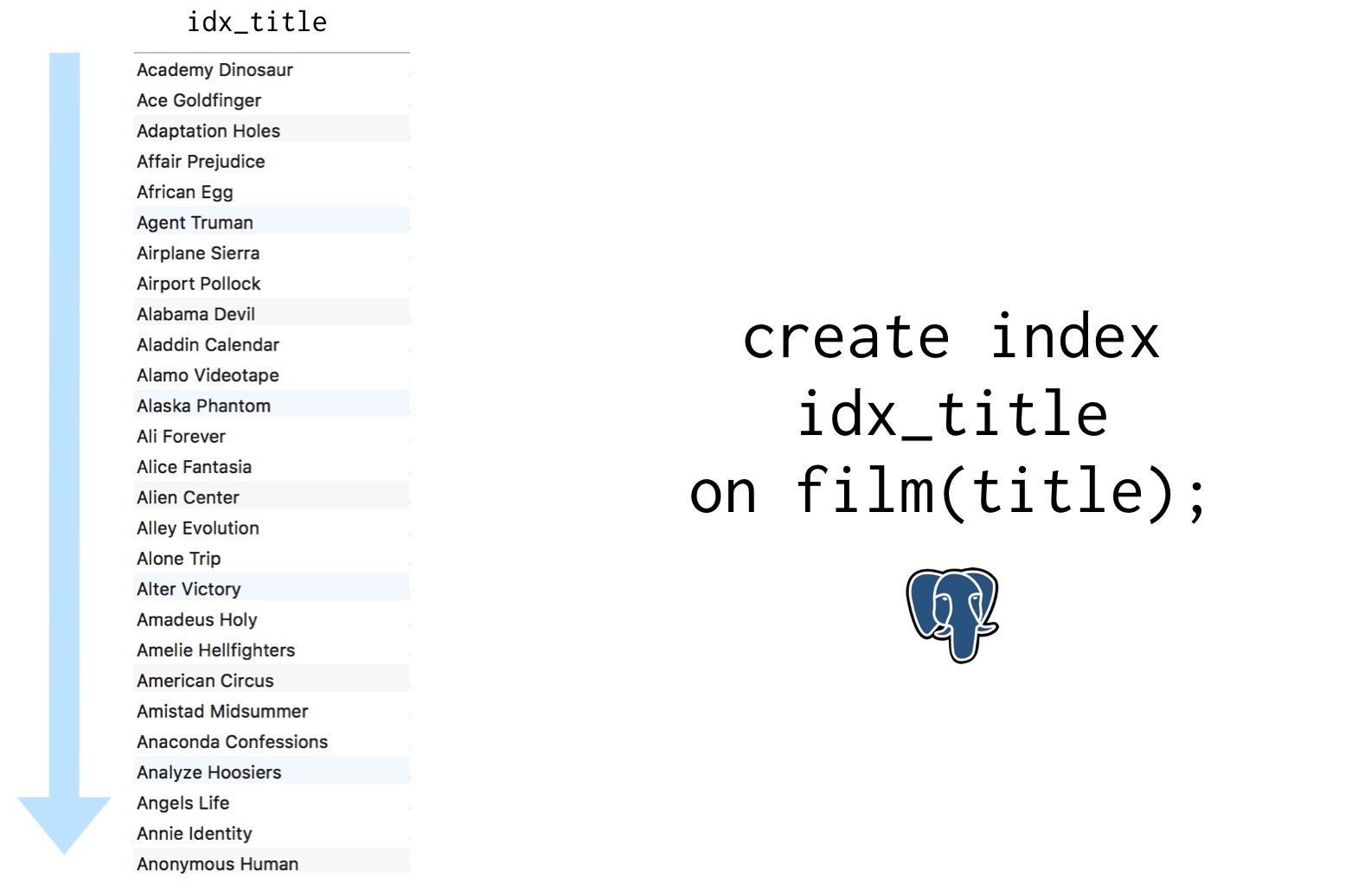
Now that the index is sorted, Postgres can find the title we’re looking for by systematically splitting this list in half until there’s only one row left, which will be the one we want.
This is much better than looping over every row (which we know is O(n)), but how many operations do we have here? For this we can use logarithms:
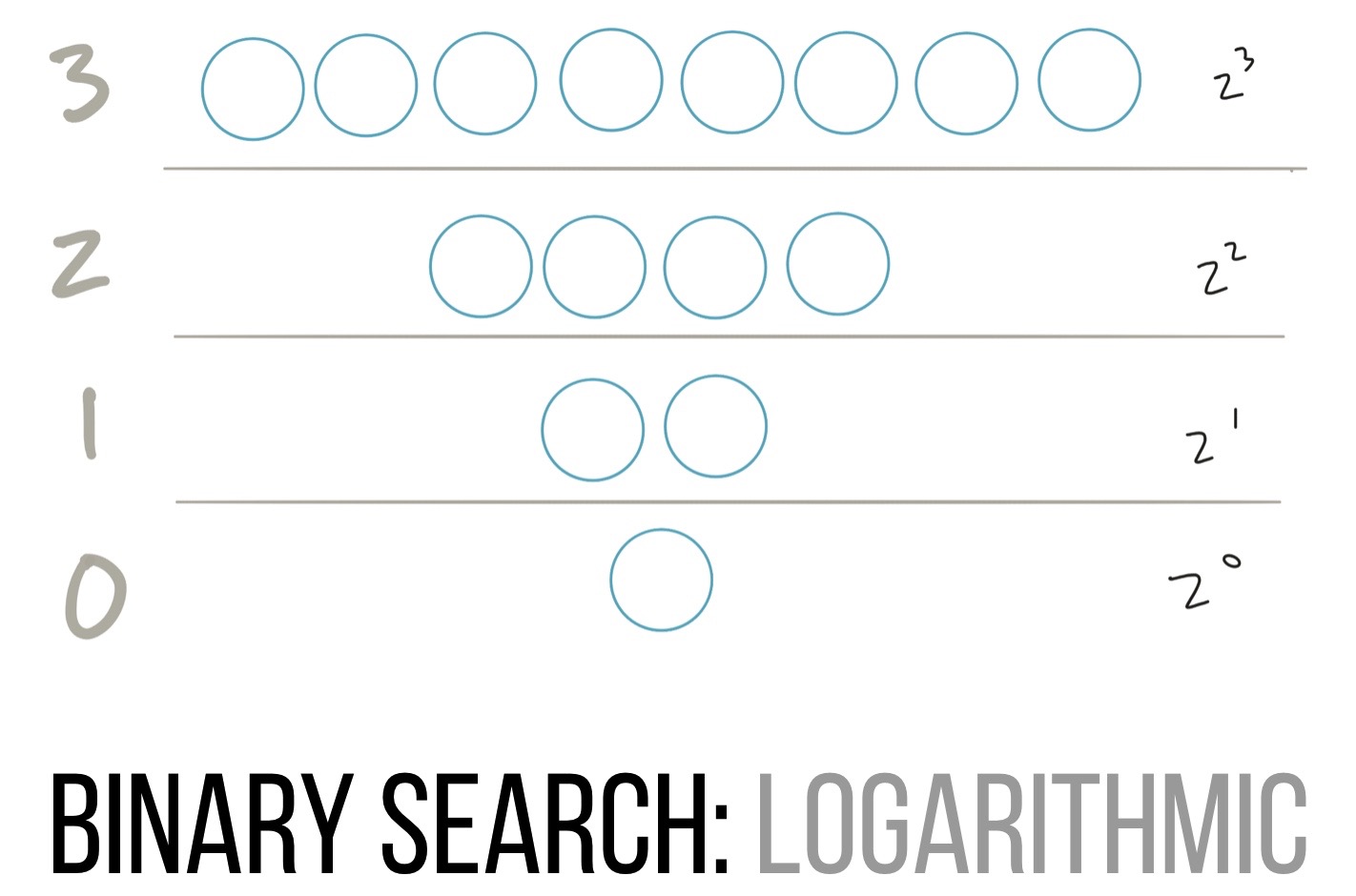
We’re continually splitting things in half in a sorted set until we arrive at the thing we want. We can describe this with an inverted binary tree, as you see above. We start with 8 values, split, and are left with 4, which we split again to get 2, then finally 1.
This is an inverse squaring operation as we’re going from 2^3 (8) down to 2^2 (4) down to 2^1 (2) and finally 2^0 (1). Inverse squaring operations are called logarithms. That means that we can now describe the operations of our database index as “being logarithmic”. We should also specify “logarithmic of what” to which we can answer “we don’t know, so we’ll say it’s n“, also known as O(log n).
This kind of algorithm is called “divide and conquer” and when you see those words, you know immediately that you’re talking about a log n algorithm.
… AND SO WHAT?
Here’s why you care about turning something that’s O(n) into O(log n) and the best part is that it’s not really arguable because it’s math (I was told that means you’re always right :trollface:).
Let’s say we have 1000 records in our film table. To find “Academy Dinosaur” our database will need to do 1000 operations (comparing the title in each row). But how many will it do if we use an index? Let’s use a calculator and find out, shall we? I need to find the log base 2 (because of the binary split) of 1000:
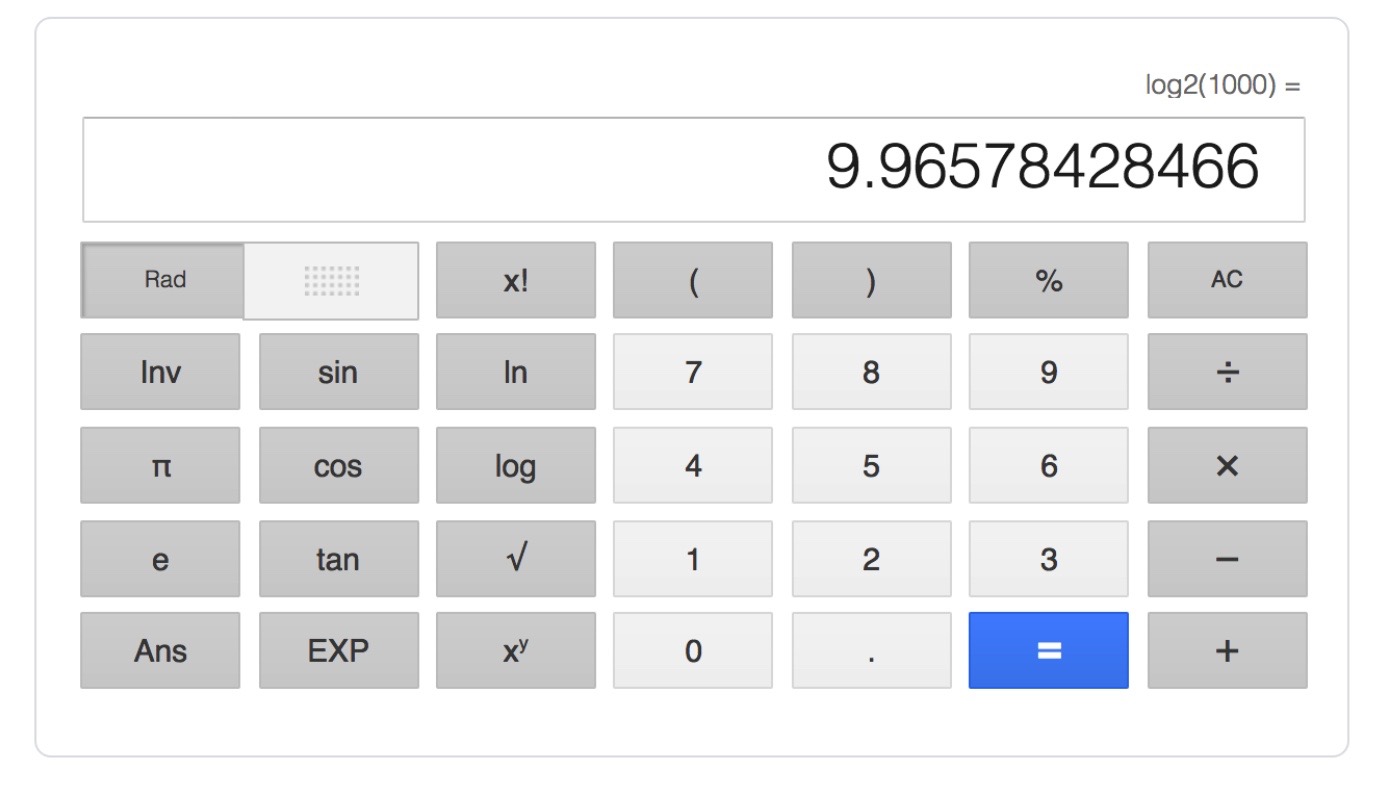
Only Ten! Ten splits of 1000 records to find what we want in our database. That’s a performance gain of a few orders of magnitude, and it’s a lot more convincing to tell someone that as opposed to “it’s a lot faster”.
The best part here is that we can keep using this calculator to find out how many operations will be needed if we have a million records (it’s 20) or a billion (it’s 30). That kind of scaling as our inputs goes up is the stuff of DBA dreams.
BONUS QUESTION: WHAT’S THE BIG O OF A PRIMARY KEY LOOKUP?
It’s tempting to think that if I have a primary key and I know the value of that key that I should be able to simply go right to it. Is that what happens? Think about it for a second and while you’re thinking let’s talk about Redis a bit more.
A major selling point of Redis (or any key-value system really) is that you can do a lot of stuff with O(1) time complexity. That’s what we’re measuring when we talk about Big O – time complexity, or long something takes given the inputs to an algorithm you’re working with. There’s also space complexity which has to do with the resources your algorithm needs, but I’ll save that for another post.
Redis is a key-value store, which means that if you have a key, you have an O(1) operation. For our Shopping Cart above, if I use a Hash I’ll have a key for the cart as well as a key for each item in the cart, which is huge in terms of performance – or I should say “optimal time complexity”. We can access any item in a cart without a single loop, which makes things fast. Super fast.
OK, back to the question regarding primary key queries: are they O(1)? Nope:
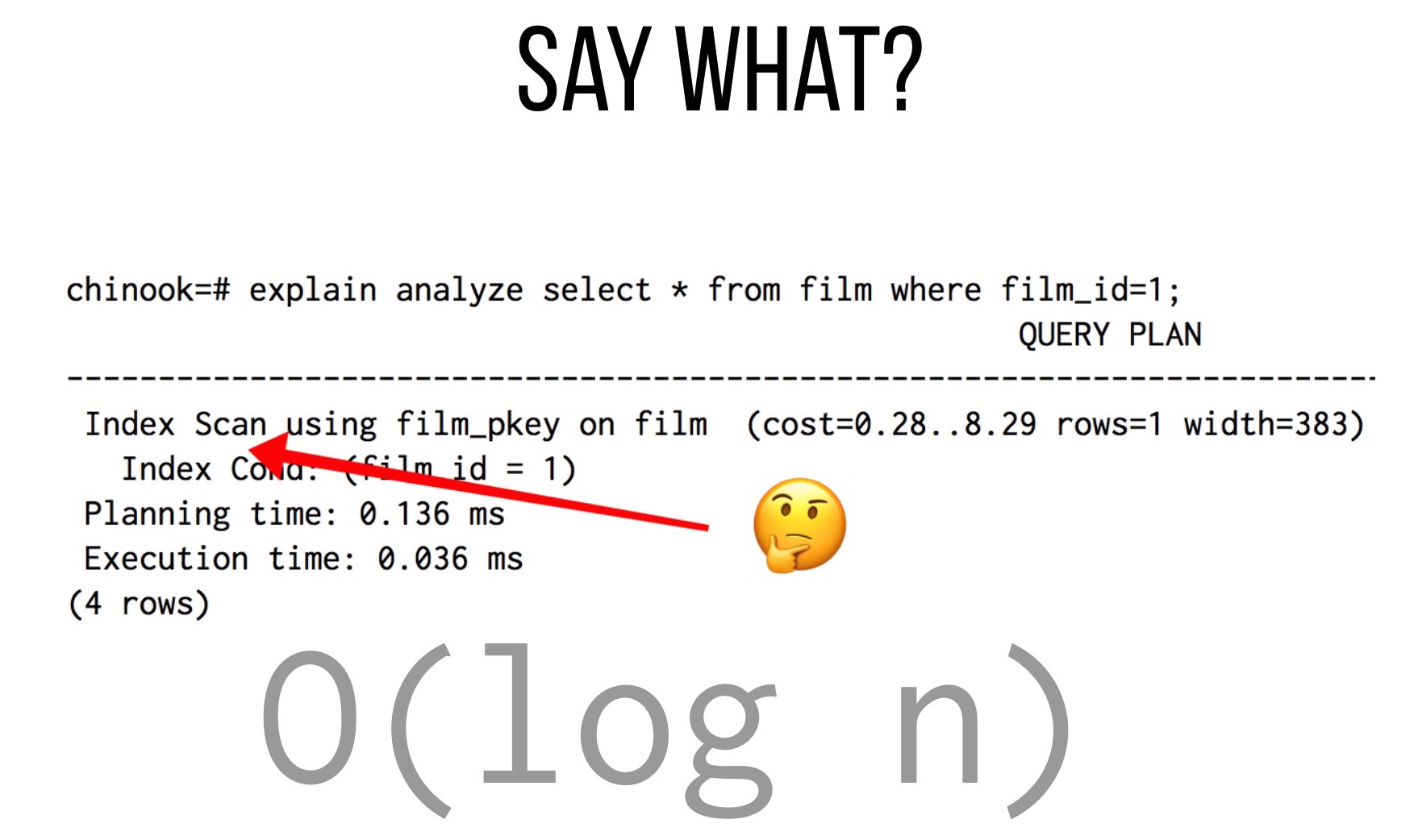
Indexes in most database systems tend to use a variation of binary search, and primary key indexes are no different. That said, there are plenty of optimizations that databases use under the covers to make these queries extremely fast.
I should also note that some databases, like Postgres, offer you different types of indexes. For instance you can use a Hash Index with Postgres that will give you O(1) access to a given record. There is a lot going on behind the scenes, however, to the point where there’s a pretty good debate about whether they’re actually faster. I’ll side step this discussion and you can go read more for yourself.
THERE YOU HAVE IT
I find myself thinking about things in terms of Big O a lot. The cart example, above, happened to me just over a month ago and I needed to make sure that I was flexing the power of Redis as much as possible.
I don’t want to turn this into a Redis commercial, but I will say that it (and systems like it) have a lot to offer when you start thinking about things in terms of time complexity, which you should! It’s not premature optimization to think about Big O upfront, it’s programming and I don’t mean to sound snotty about that! If you can clip an O(n) operation down to O(log n) then you should, don’t you think?
So, quick review:
- Plucking an item from a list using an index or a key: O(1)
- Looping over a set of n items: O(n)
- A nested loop over n items: O(n^2)
- A divide and conquer algorithm: O(log n)